4 min read
You can’t manage what you can’t see. That’s the basic premise of much of Bedrock’s efforts to improve how organizations protect their data, ensure legal compliance, and reduce their overall risk.
To efficiently and accurately find and organize complex and unique data sets across cloud environments, we divide the efforts of our AI-powered architecture into five layers that each work together to provide robust data visibility and control. Each higher layer builds off the lower layers to add more context and extract more meaning about each dataset in an organization’s data environment.
Powering our five-layer architecture are three core Bedrock technologies that make our platform the fastest and most cost-efficient data security tool on the market. Combined, these capabilities make it far more affordable for organizations to gain a complete, accurate, and continuous view of all their data, helping them greatly improve their data security and compliance efforts.
The Bedrock Architecture: Five Layers for Complete Data Visibility
Each layer in the Bedrock architecture builds upon the next layer to provide unprecedented speed and accuracy for data scanning and classification.
BEDROCK SECURITY’S FIVE-LAYER ARCHITECTURE
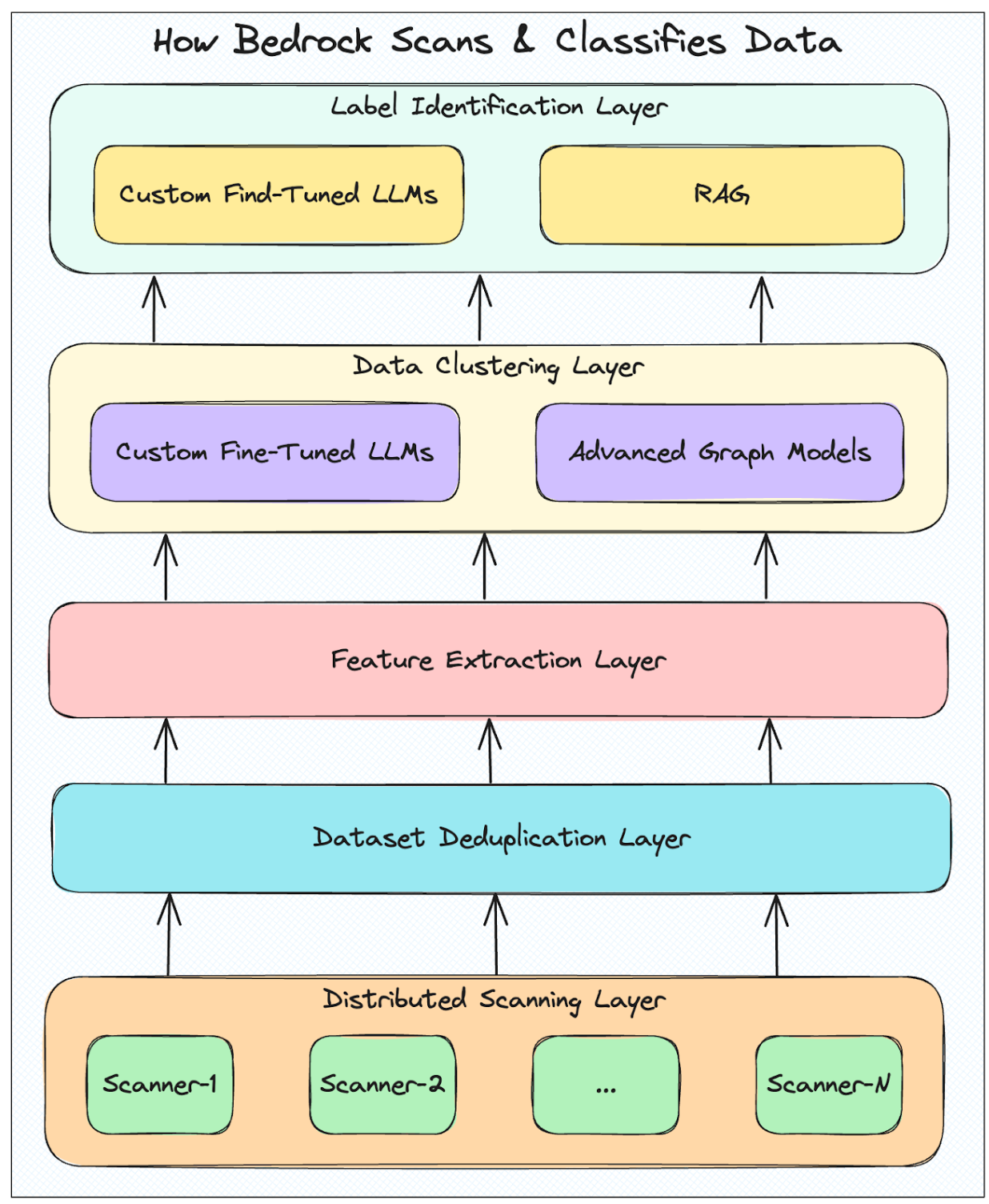
Layer 1: Distributed Scanning Layer
The base layer of our AI-powered architecture focuses on deploying scalable, highly efficient scanners working in parallel to discover and categorize data across the most complex cloud environments.
Layer 2: Data Deduplication Layer
Once scanned, data is then processed through a deduplication layer designed to identify data sets that are identical. We identify clusters of similar data sets and sample a few documents per cluster to increase the efficiency of our classification.
Layer 3: Feature Extraction Layer
In the third layer, we generate a representation of each individual dataset with extracted keywords and embeddings, providing the metadata needed to track and manage customer data without moving it out of their environments.
Layer 4: Data Clustering Layer
Utilizing a combination of graph models and advanced large language models, we identify and cluster similar data sets, selecting the most accurate results through an evaluation process to ensure consistent classification and identifying access pathways.
Layer 5: Label Identification Layer
In the top layer of the Bedrock architecture, we ensure highly accurate, coherent labels for each cluster and its constituent documents using our custom, fine-tuned LLMs and retrieval-augmented generation.
The Technology Pillars to Bedrock’s Hyper-Efficient Architecture
The foundation to Bedrock’s five-layer architecture is powered by three areas of innovation.
ADAPTIVE SAMPLING
Bedrock Adaptive Sampling technology is driven by state-of-the art ML models, transforming raw data into rich, actionable insights. We use our private LLMs to categorize documents in ways that are not just based on data types.
For example, in addition to identifying that a document has a social security number in it, the Bedrock platform can tell that the document is a W-2 form, which then makes it possible to determine that those documents are part of HR-related data. That's where our LLMs come in. They read keywords that have been extracted out of the document and are able to concisely summarize what the document actually is.
Overall, Bedrock Adaptive Sampling technology needs less information about scanned data sets to accurately identify them. This provides the first pillar in Bedrock’s unrivaled data scanning efficiency.
PARALLEL, SERVERLESS SCANNING
The Bedrock platform also provides increased efficiencies in how we manage the serverless “workers” that run in parallel to scan data sets.
For example, if you have to look at a billion data files, how do you split up the tasks among all those workers? Those files are likely scattered across multiple directories. Some directories are going to have millions of files, some directories are going to have ten files.
To make our parallel scanning as scalable and efficient as possible, we don’t use a single, coordinated node that assigns the work. Instead, we use a distributed system without any master nodes. In this way, the coordination of the work is also distributed, like the workers.
Critically, we build sophisticated guidance into our crawler to make the coordination of this highly parallelized work far more efficient than standard approaches. In other words, our parallel workers and management system are smart. If a worker takes on more work than it can process, it knows how to split up the task that it has taken and put the remaining work back into the queue for others to pick up. This helps each worker perform most effectively and avoid becoming overwhelmed with tasks and slowing down the scan process.
Overall, our custom crawler and serverless architecture provides highly elastic scale, allowing us to deploy thousands of workers as needed to complete scans ten times faster than traditional data security posture management (DSPMs) tools.
FINGERPRINTING
Bedrock fingerprinting technology is the third technology pillar of the Bedrock architecture. In our scans, we compare not just the exact similarity of data sets but also look at the similarity of the schema (if it's a structured data set). This allows us to create unique “fingerprints” for data sets that are far more intelligent and less brittle than using rigid RegEx search rules for tracking data.
These detailed data fingerprints make it possible to track the movement of data, and, critically, identify copies or derivative versions of sensitive data very quickly. If a database or a spreadsheet is copied, moved, and modified, our fingerprinting will match those as being part of the same lineage.
We also have the ability to do fine-grained as well as coarse-grained fingerprinting. The granularity of the fingerprinting is dynamically changed based on the type of data. If it's a huge data lake or large database, then we don't need to fingerprint every single byte of the data. We just fingerprint a small percentage and then we know what the data set is about.
But if it's a document, we might need to fingerprint those in much greater detail, typically fingerprinting every word in the document. This fine-grained fingerprinting is incredibly helpful for organizations looking to protect their most sensitive data, such as intellectual property.
To learn more about how the Bedrock platform can help improve your data security, read the white paper “The Path to Frictionless Data Security” or speak with our data security experts.