5 min read
Metadata Lake - The Missing Link Between Data Producers And Data Consumers
Bruno Kurtic : Mar 16, 2025 7:35:44 PM
In today’s digital economy, data is the fuel driving enterprise innovation. Cloud technologies, AI-driven workloads, and agile development empower organizations to move faster and, as a byproduct, create unprecedented volumes of both structured and unstructured data.
While this explosion of data, when properly leveraged, fuels competitive advantage, it also introduces new layers of complexity and risk. Security, governance, and data leaders now face the challenge of managing a dynamic, sprawling, ever-evolving data landscape without losing sight of its value.
The surge of enterprise initiatives adopting generative AI and large language models (LLMs) further complicates this scenario: data isn’t just expanding in volume—it’s also being synthesized into novel outputs, potentially exposing sensitive information in unexpected ways. Once a model is trained, it effectively becomes a ‘black box,’ making it impossible to fully predict what content might emerge in the output. The only reliable safeguard is robust data inspection before feeding datasets into AI, reinforcing the need for continuous, context-rich data oversight.
CISOs rate AI data usage governance as their top priority (83%) for 2025. (Bedrock 2025 Enterprise Data Security Confidence Index)
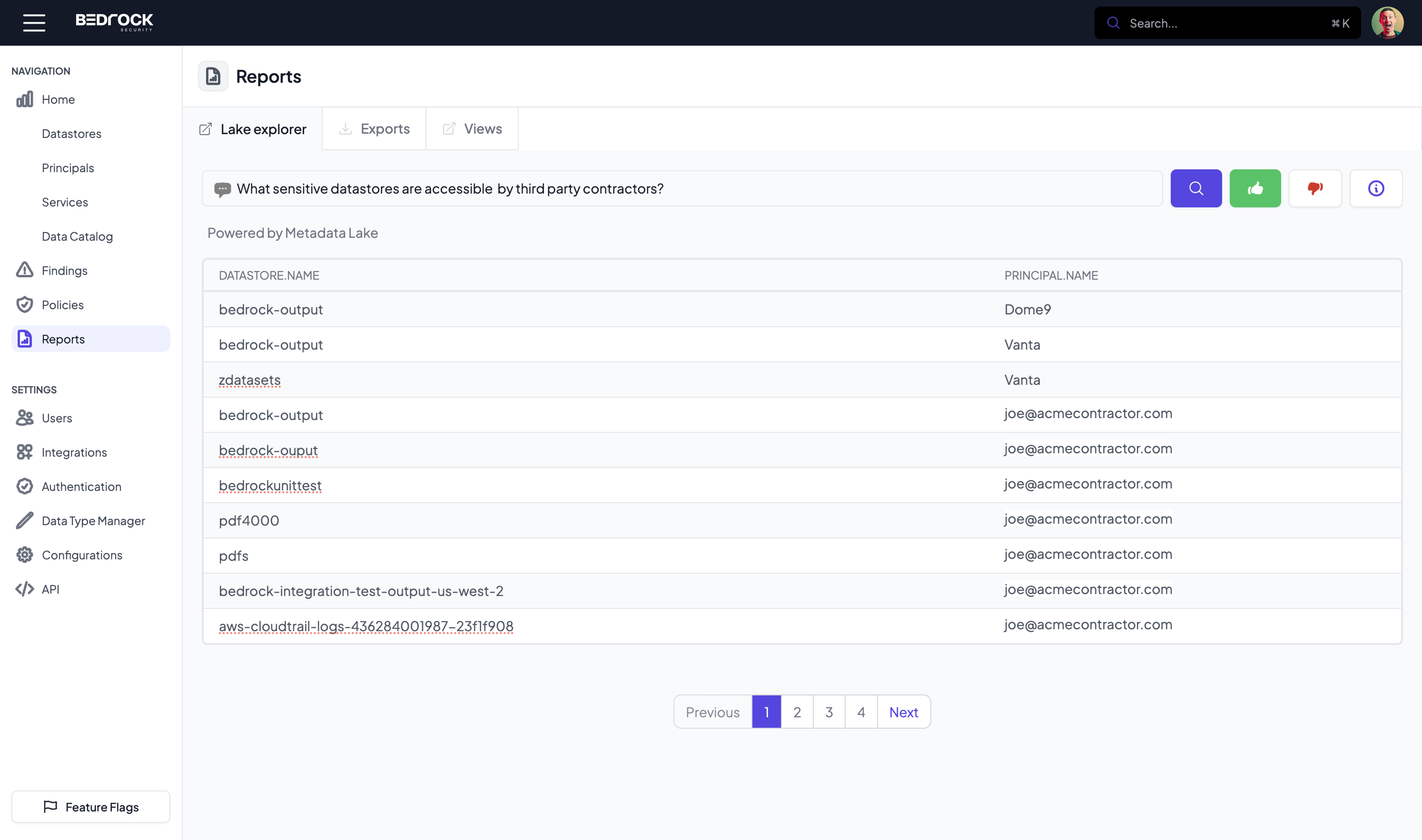
At Bedrock Security, we believe that the key lies in metadata—the rich, contextual layer that reveals what data exists, where it resides, how sensitive it is, how it moves, who has access to it and more. We propose that there is a need for an enterprise wide data asset repository that contains critical contextual information about enterprise datasets and data stores and we propose a name for it: Metadata Lake.
A Game Changer For Data Security And Data Management
For decades, security has been built around endpoints, networks, and identities—even though data is the very asset we’re trying to protect. Traditionally, organizations have focused on locking down potential access points rather than directly securing the data itself.
Traditional DSPM (data security posture management) tools were built with a singular focus on detecting sensitive data, and their back ends were designed solely for that purpose. This approach may partially solve that singular problem but it creates yet another silo of information. Today’s data is a shared responsibility across engineering, security, data governance, line of business, IT, and more—each group asking different questions about the same data, thus a new approach to data security, data management, and ultimately to DSPM is needed.
A Metadata Lake changes the game by offering a comprehensive, continuously updated view of all enterprise data. Built as a flexible knowledge graph, it provides deep insights into what data exists, where it resides, how sensitive it is, how it moves, who has access to it, and more—all in one place—empowering cross-functional teams to instantly understand whether data is sensitive, authorized for usage, and compliant, without the manual overhead of assessments, Jira tickets, or approvals. Teams can thus move faster, confidently leveraging data without risking security or violating GRC controls.
Nearly 90% of organizations value a metadata lake approach for continuous data discovery and classification. (Bedrock 2025 Enterprise Data Security Confidence Index)
What Makes a Metadata Lake Different?
1. API-First: Data Context for Every Tool and Process
A true Metadata Lake isn’t just another siloed repository—it’s API-first, designed to share data context with all your existing security, compliance, and data management tools. Whether you’re integrating with a SIEM to prioritize alerts by actual data sensitivity, or feeding entitlements into a governance platform for real-time policy enforcement, the Metadata Lake provides live, on-demand insight into which data exists, where it resides, and how important it is. By delivering a single “source of truth” for enterprise data context, it ensures every workflow—DSPM, data governance, threat detection, vulnerability management, privacy, incident investigation, data management, or BI analytics—can work with up-to-date intelligence.
2. Push-Down Tag Syncing: Labeling Datasets at Their Source
Rather than keeping labels and classifications locked inside a separate system, our approach pushes tags directly into the original data stores. That means if a table in Snowflake, a file in SharePoint, or an object in S3 is classified as “PII” and/or “Critical IP” and/or gets an AI derived semantic label like “HR document,” we update that classification right at the source. This push-down tag syncing ensures consistent policies—like retention, access control, or encryption—can be automatically enforced. In other words, the Bedrock Metadata Lake doesn’t just store metadata; it pushes that metadata to where it matters most—where datasets reside—so data is always labeled and controlled.
3. Copilot: Ask the Metadata Lake Anything
One of the most transformative capabilities we’re launching is Copilot, allowing you to ask the Metadata Lake questions about your data in plain language. Want to know who accessed a particular dataset or its derivatives in the last month or whether contractors have access to data with Primary Account Numbers (PANs) in a certain region? Copilot can answer in real time, drawing on the lake’s rich graph of classification, entitlement and lineage context. This goes beyond rigid dashboards or SQL queries: Copilot leverages the metadata lake’s flexible knowledge graph and interprets natural language to answer your specific use case questions and further, can deliver context-rich answers to a wide variety of questions that may come from different personas in the enterprise. And with our upcoming Agentic AI capability, this will further enhance the intelligence and productivity of enterprise security, governance, and data management teams,
4. Built on a Flexible Graph Structure
At the heart of this innovation is a graph engine that models complex relationships—like lineage, role chaining, or data similarity—in a far more natural way than traditional tables. Because data rarely follows a neat hierarchical path in modern enterprises, the graph is uniquely suited to capture those many-to-many links between datasets, users, cloud services, and compliance policies. This is why our Metadata Lake can adapt to new data sources, rapidly changing AI workloads, and shifting regulatory requirements without forcing an extensive reconfiguration or redesign each time.
By fusing an API-first design, push-down labeling, intuitive Copilot capabilities, and a flexible graph core, Bedrock’s Metadata Lake ensures your security, compliance, and data engineering teams all have immediate, actionable context on every dataset—no matter where it lives or how quickly it changes.
Three Core Pillars of a Modern Metadata Lake
If you can’t scale, you have blind spots: a scalable, continuous discovery process lies at the heart of any effective metadata lake. It ensures near-real-time updates of data location and state—without running up exponential costs—even as data volumes balloon across IaaS, PaaS, and SaaS. By continuously scanning and tracking newly created or modified assets, a metadata lake remains current in spite of ever-changing data footprints, preventing blind spots before they arise.
If you can’t see beyond patterns, you miss the bigger picture: next, AI-powered contextualization goes well beyond basic pattern detection. Instead of merely flagging PII or PHI at a field level, it captures business relevance, document topics, and regulatory categories for each dataset. This semantically enriched classification means cross-functional teams—security, governance, and data engineering—can leverage richer context to ensure data is used effectively, minimize risk, and align data management decisions with business value rather than relying on purely atomic classification signals.
If you can’t see usage and entitlements, you can’t fully assess or contain risk: finally, end-to-end entitlement and usage analysis provides crucial visibility into who can access specific datasets, plus who actually does. By correlating entitlement paths with real usage patterns, security and governance teams can align access decisions to the dataset’s sensitivity and usage context, minimizing risk and ensuring data remains available to those who truly need it.
From Data Silos to a Live Data Supply Chain: A Paradigm Shift
A live enterprise data asset context repository—where information no longer exists in silos—heralds a shift in how organizations use and protect their data. By unifying data context into a single, flexible, enterprise-wide repository for use by security, governance, and data management, the Metadata Lake becomes the layer that ties all teams together with continuous, contextual insights. No longer must data remain an elusive or siloed resource; now, everyone in the enterprise can tap into a continuous, ubiquitous, AI-driven context to innovate faster and safeguard critical assets. It’s a paradigm shift—one that positions the enterprise to thrive safely in a data-centric future.
To know more, visit our site. You can also contact us for more information.